Ara que portem uns dies guardant métriques, poso alguna cosa.
No hi han agut problemes últimamente (que sepi) més enllá de que la linea de notificacions es forsa lenta.
El que he vist es que la máquina té molt poc marge de recursos. Miraré a veure el tema de purgar dades com seria, pero ara mateix es sol pasar del Load Average (tot va lent, així en general) i de la RAM está justisima.
Aixó son les métriques dels últims dies.
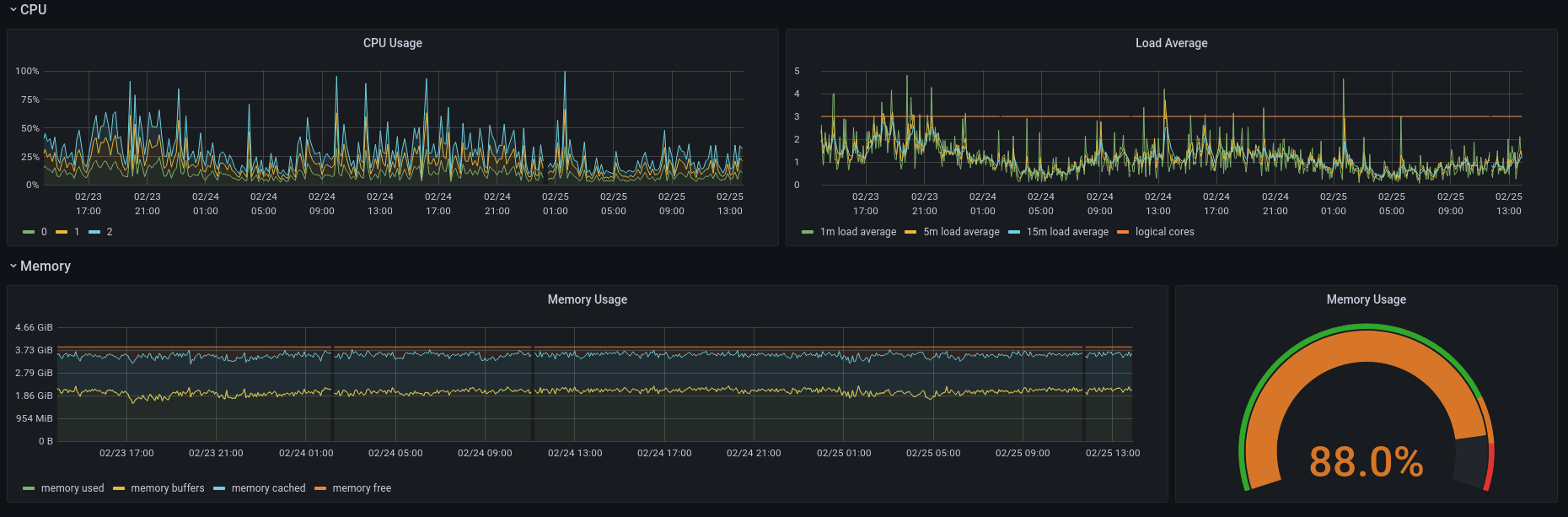
Faré un backup de la base de dades i aniré aplicant les propostes de la DB de la documentacío de pleroma, que comentava més amunt.