Si us semble be, per mi perfecte. No prometo poder arreglar gaire, només donar un cop d’ull, per aixó x)
1 'M'agrada'
Doncs he estat donant un cop d’ull, comento coses que he vist. Algunes ja s’han comentat, pero es tan llarg aixó que potser va bé un resum.
TL;DR
L’única cosa que veig a millorar es posar la configuració de queue_target y queue_interval. Sembla que está tot ben configurat.
Aniria ve poder tenir métriques, tant de pleroma com de nivell básic de la máquina. Si voleu, puc configurar al servidor per a que que exposi métriques i les recullo i processo al meu stack de monitorizació.
Análisis de l’error
Error de Pleroma
L’error principal es que pleroma deixa de funcionar degut a que s’encuen les peticiones que te que fer a la base de dades. L’error es el que s’ha posat:
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: 05:10:57.712 [error] GenServer {Oban.Registry, {Oban, {:producer, "mailer"}}} terminating
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: ** (DBConnection.ConnectionError) connection not available and request was dropped from queue after 1442ms. This means requests are coming in
and your connection pool cannot serve them fast enough. You can address this by:
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: 1. Ensuring your database is available and that you can connect to it
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: 2. Tracking down slow queries and making sure they are running fast enough
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: 3. Increasing the pool_size (albeit it increases resource consumption)
Jan 2 05:10:57 pleroma-bcn-social pleroma[17020]: 4. Allowing requests to wait longer by increasing :queue_target and :queue_interval
En la segona linea ens diu ja quines son les possibilitats que provoquen l’error.
- Que la base de dades estigui caiguda: Hem confirmat que no es així.
- Que comprovem peticions lentes a la base de dades: Per a mi, es l’últim que tindriem que mirar ja que es una cosa de pleroma.
- Fer més gran el
pool_size: es el número de conexión que permet Pleroma obrir contra la base de dades. Aixó ja está canviat, així que no tindria que ser un problema. - Permetre a les peticiones esperar més estona: Em sembla raonable, pero es una merda trobar documentació sobre aixó. En issues he vist que el porimer parámetre surt, pero el segon no. També he vist a la configuració que s’ha intentat i no ha funcionat (o aixó diu el comentari). Algú sap algo?
pool_size: 30
# failed config
# pool_size: 20,
# timeout: 60_000,
# queue_target: 1000,
# queue_interval: 15000
Error de Postgres
Ademés, he donat un cop d’ull als logs de la base de dades i he vist una cosa que pot ser interessant:
2023-01-03 19:36:48.438 CET [27027] user@db LOG: could not send data to client: Broken pipe
LIKE 'internal.%'))
2023-01-03 19:36:48.438 CET [27027] user@db FATAL: connection to client lost
2023-01-03 19:40:15.235 CET [28166] user@db LOG: unexpected EOF on client connection with an open transaction
2023-01-03 19:40:15.254 CET [28164] user@db ERROR: canceling statement due to user request
Aquests missatges transmeten una cosa molt concreta. Pleroma es conecta a la base de dades, postgres processa la petició pero Pleroma es desconecta de postgres. Per aixó no pot respondre.
Aixó passa tant en consultes de llegir com d’escriure. Lo cual es un problema, perque sembla que després Pleroma reintenta la petició, logicament, pero a la base de dades ja s’ha executat. Per lo tant dona errors perque Pleroma li diu que executi accions que ja estan executades. Per exemple:
2023-01-03 20:00:42.648 CET [28211] user@db LOG: could not send data to client: Broken pipe
2023-01-03 20:00:42.648 CET [28211] user@db FATAL: connection to client lost
2023-01-03 20:01:27.901 CET [28183] user@db ERROR: duplicate key value violates unique constraint "users_nickname_index"
2023-01-03 20:01:27.901 CET [28183] user@db DETAIL: Key (nickname)=(agenda@bcn.convoca.la) already exists.
2023-01-03 20:01:27.901 CET [28183] user@db STATEMENT: UPDATE "users" SET "follower_address" = $1, "last_refreshed_at" = $2, "name" = $3, "nickname" = $4, "updated_at" = $5 WHERE "id" = $6
2023-01-03 20:01:27.941 CET [28184] user@db ERROR: duplicate key value violates unique constraint "users_nickname_index"
2023-01-03 20:01:27.941 CET [28184] user@db DETAIL: Key (nickname)=(agenda@bcn.convoca.la) already exists.
2023-01-03 20:01:27.941 CET [28184] user@db STATEMENT: UPDATE "users" SET "follower_address" = $1, "last_refreshed_at" = $2, "name" = $3, "nickname" = $4, "updated_at" = $5 WHERE "id" = $6
...
Aquí li diu Pleroma a la DB que actualitzi/creei l’usuari agenda@bcn.convoca.la. Lo cual dona els errors de duplicate key mooolts cops.
Aixó últim no se si es relevant pel problema que ens ocupa. El que si que queda clar es que cuan Pleroma cau, la Postgres es queda reintentan contestarli l’última petició que ha fet.
Operacions de manteniment
No se si ja es fan, pero també es podrien executar algunes operacions mencionades aquí. Concretament:
- Prune old remote posts from the database¶
- Remove duplicated items from following and update followers count for all users¶
- Vacuum the database¶
- Full¶
Monitorizació
Per últim, crec que s’ha de descartar tema de recursos. En general tot está ben configurat, em sembla bastant extrany que hi hagin aquest tipus de errors. Per aixó crec que seria bo instalar el Node Exporter, activar les métriques de Pleroma i recollir aquestes métriques al meu sistema de monitorizació. Podria crear usuaris per a que pogueu consultar i si es veu que val la pena, es pot montar un propi del colectiu, pero per comensar em sembla el més rápid.
- GitHub - prometheus/node_exporter: Exporter for machine metrics
- Prometheus Metrics - Pleroma Documentation
Opinions?
Doncs aixo x)
1 'M'agrada'
En primer lloc, gràcies per l’anàlisi!! ![]()
Crec que va ser el @tuttle . Podríem explorar-ho més.
Sense dubte es podríen fer i potser alleugarien la base de dades.
Per mi perfecte! Endavant ![]()
Aquests dies ha caigut algunes vegades. Quina frustració!!! Potser podríem per explorar més el pool_size i fer neteja de manteniment.
Salut!
Nice, vaig comentant si toco.
Per cert, no ho vaig dir, pero vaig mirar el tema de les notificacions que triguen. Es donarli a carregar notificacions i la CPU es posa al máxim casi O.o Hi han coses més urgents que potser ho arreglen, pero em sembla molt extrany.
1 'M'agrada'
Hola,
A mi des de la interfície web em continuen sortint els “500 Internal Server Error” des de fa força temps, de manera que no puc utilitzar realment la web. Només em queden els clients mòbils, dels quals el Husky sembla que va bé, i el Fedilab no (no pot carregar missatges, no sé per què, però sí curiosament enviar-ne).
Sabeu com està la cosa? Teniu disponibilitat per anar gestionant aquestes incidències? Malauradament no tinc gens d’experiència amb això de gestionar aplicacions web complexes i amb un ús més o menys intensiu de recursos (sí he fet coses molt simples amb PHP + MySQL), així que no veig com ajudar sense que impliqui una dedicació molt gran de temps per aprendre (cosa per a la qual ara no tinc disponibilitat). Igual si hi ha alguna cosa que sí pugui fer (testing, per exemple?) estaria encantat de contribuir.
Salut i gràcies per la feina!
3 'M'agrada'
Hola Eudaimon!
Doncs és curiós, jo faig servir web i aplicació mòbil (Husky). A la web a vegades m’apareixen, sobretot quan el tinc obert una estona. Tot i així, en general puc fer-ne un ús més o menys productiu. He de dir que crec que ho reviso més des del mòbil, tot i així.
Doncs alguna cosa vam avançar perquè sembla que ja no salta com abans. Tot i així hi ha marge de millora, és evident. Sí que tinc intenció de ficar-m’hi, però entre que estem migrant alguns dels servidors amb en @tuttle i la feina d’administració que també tinc a anartist tinc el temps limitat. I a més vaig més lent perquè no sóc sysadmin de veritat ![]() . Però sí que m’agradaria provar d’implementar les millores que va apuntar el @drymer .
. Però sí que m’agradaria provar d’implementar les millores que va apuntar el @drymer .
En qualsevol cas, gràcies per l’interès i per l’oferiment d’ajuda! Intentaré tenir aquest fil actiu perquè no sembli que ho hem abandonat.
2 'M'agrada'
Holi! Sorry, que vaig dedicant temps a ratos molt llargs.
Jo he reiniciat un parell o tres de cops el servei de pleroma en el mes, mes y pico anterior, tots cops amb la mateixa situació. Ahir vaig acabar de configurar cosetes per tenir métriques al meu stack de monitorizació. Recullo métriques a nivell de SO y de postgres. De pleroma també, pero son bastant pobres i tindré que fer algún dashboard.
Si us sembla, si en algún moment algú veu que está pillat el servei y el reinicia, que comenti per aquí pls, per mirar métriques.
Es fan backups a algun lloc de la db? Estaba pensant en fer-ne un i executar les operacions de manteniment que vaig comentar anteriorment.
PD: intentaré en algun moment donar access a qui vulqui per veure les metriques, pero tinc que fer cosetes primer per a fer que es vegi nomes lo referent a barcelona.social, que tinc coses personals i d’altres colectius.
2 'M'agrada'
Ei, merci per dedicar-hi temps!!!
La veritat és que últimament estic més al compte que tinc a anartist. Intentaré estar-hi més per a detectar anomalies.
Els backups els fa el @tuttle, segur que en té de la db.
Perfecte.
Ara que portem uns dies guardant métriques, poso alguna cosa.
No hi han agut problemes últimamente (que sepi) més enllá de que la linea de notificacions es forsa lenta.
El que he vist es que la máquina té molt poc marge de recursos. Miraré a veure el tema de purgar dades com seria, pero ara mateix es sol pasar del Load Average (tot va lent, així en general) i de la RAM está justisima.
Aixó son les métriques dels últims dies.
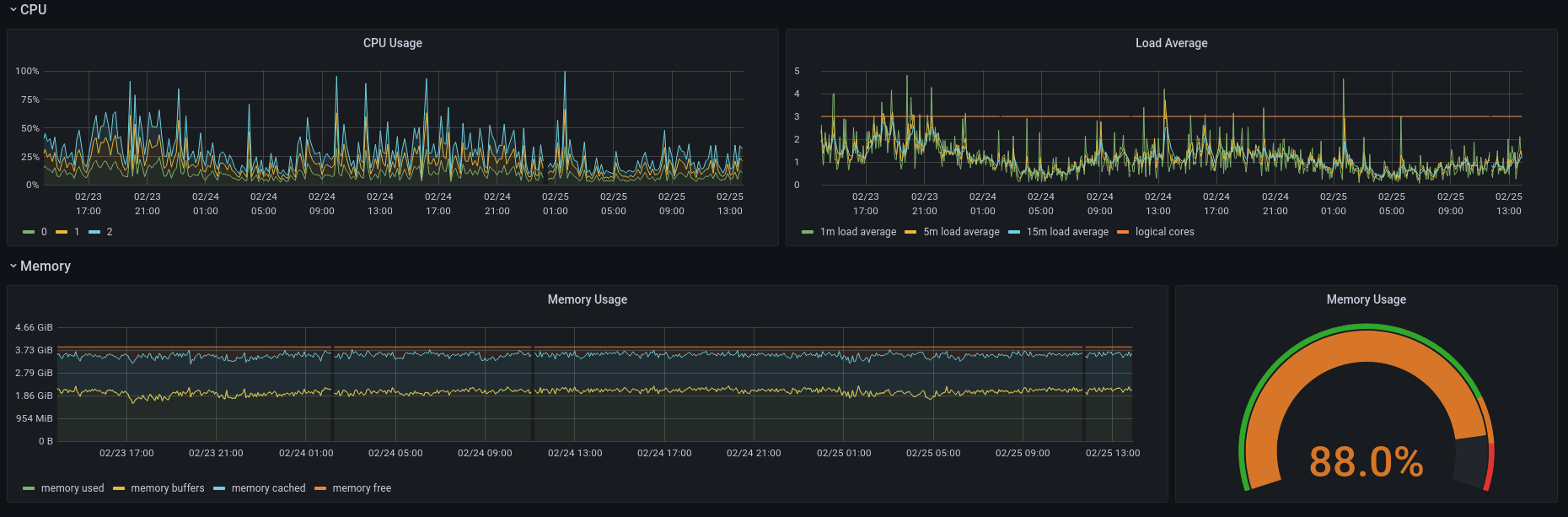
Faré un backup de la base de dades i aniré aplicant les propostes de la DB de la documentacío de pleroma, que comentava més amunt.
2 'M'agrada'
Sorry doble post, estic executant les ops de manteniment de la DB, segurament no vagin coses o vagin malament.
PD: Ja esta, a les 20:40. Aviam que tal els seguents dies.
1 'M'agrada'
Hola!
El servidor està caigut i no puc accedir-hi via ssh.
El domini no torna la IP de la máquina, em sembla que ha caducat 
Pot ser?
❯ dig barcelona.social
; <<>> DiG 9.18.11 <<>> barcelona.social
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 34441
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;barcelona.social. IN A
;; Query time: 49 msec
;; SERVER: 192.168.0.161#53(192.168.0.161) (UDP)
;; WHEN: Sun Feb 26 11:33:03 CET 2023
;; MSG SIZE rcvd: 45
1 'M'agrada'
@blankfosk , tu tenies el domini, no?
he entrat per dir el mateix. El domini no resol :S
1 'M'agrada'
Ja està. No sabem perquè però s’havia desconfigurat la redirecció del domini.
Haurem d’estar atents ara perquè tindrà càrrega retrassada…
1 'M'agrada'
Holi. He estat mirant les métriques i estan exactament iguals que l’últim dia que les vaig posar, amb els canvis a la DB aplicats i tot. Tot i així no ha estat donant problemes, que hagi vist.
Jo diria que simplement hem estem arribant al máxim que la máquina suporta.
Si es va fent el manteniment de la DB i no hi entra gaire més gent al servidor, jo crec que aguantará be. Si ve més gent, potser s’haurá de plantejar pujar la mida de la máquina. Pero bueh, ja es veura si passa.
1 'M'agrada'
Holi de nou.
Em passa que cuan carrego la página de cero, no em carrega el TL principal, i no em deixa anar enrere, em torna errors 500. Pero si deixo la página quieta, si que va carregant tots els posts nous. Us passa a algú més?
1 'M'agrada'
A mi sí que em carrega el timeline principal principal si la deixo quieta. Les notificacions tarden més, però també es carreguen.
El que no em genera bé és el timeline local. Surten entrades de fa mesos però crec que en falten de més recents.
@marcelcosta Vas entrar el divendres per que s’havia caigut la postgres un altre cop? He tingut que entrar ara per aixó u.u
1 'M'agrada'
Sí!
Crec recordar que vaig reiniciar nginx i pleroma.